如何构建有效的代理
Over the past year, we’ve worked with dozens of teams building large language model (LLM) agents across industries. Consistently, the most successful implementations weren’t using complex frameworks or specialized libraries. Instead, they were building with simple, composable patterns.
过去一年,我们与数十个团队合作,构建了跨行业的LLM大型语言模型代理。始终如一的是,最成功的实现并没有使用复杂的框架或专门的库。相反,他们使用简单、可组合的模式进行构建。
In this post, we share what we’ve learned from working with our customers and building agents ourselves, and give practical advice for developers on building effective agents.
在这篇文章中,我们将分享我们从与客户合作和构建代理的过程中学到的知识,并为开发者提供构建有效代理的实用建议。
What are agents? 代理是什么?
“Agent” can be defined in several ways. Some customers define agents as fully autonomous systems that operate independently over extended periods, using various tools to accomplish complex tasks. Others use the term to describe more prescriptive implementations that follow predefined workflows. At Anthropic, we categorize all these variations as agentic systems, but draw an important architectural distinction between workflows and agents:
“Agent”有多种定义。一些客户将 agent 定义为完全自主的系统,可以长时间独立运行,使用各种工具来完成复杂的任务。另一些客户则用该术语来描述遵循预定义工作流程的更规范的实现。在 Anthropic,我们将所有这些变体归类为代理系统,但在工作流程和代理之间划清了重要的架构界限:
- Workflows are systems where LLMs and tools are orchestrated through predefined code paths. 工作流是LLMs和工具通过预定义的代码路径进行编排的系统。
- Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks. 另一方面,代理是LLMs动态指导自身流程和工具使用、维护对任务完成方式控制的系统。
Below, we will explore both types of agentic systems in detail. In Appendix 1 (“Agents in Practice”), we describe two domains where customers have found particular value in using these kinds of systems.
下面,我们将详细探讨这两类代理系统。在附录 1(“实践中的代理”)中,我们描述了客户在使用这些类型的系统中发现特殊价值的两个领域。
When (and when not) to use agents
何时(以及何时不)使用代理
When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all. Agentic systems often trade latency and cost for better task performance, and you should consider when this tradeoff makes sense.
使用LLMs构建应用程序时,我们建议找到尽可能简单的解决方案,并且仅在需要时才增加复杂性。这可能意味着根本不构建代理系统。代理系统通常会牺牲延迟和成本来换取更好的任务性能,您应该考虑何时这种权衡是合理的。
When more complexity is warranted, workflows offer predictability and consistency for well-defined tasks, whereas agents are the better option when flexibility and model-driven decision-making are needed at scale. For many applications, however, optimizing single LLM calls with retrieval and in-context examples is usually enough.
当需要更高的复杂性时,对于明确定义的任务,工作流提供了可预测性和一致性,而当需要大规模的灵活性和模型驱动的决策时,代理是更好的选择。然而,对于许多应用程序来说,通过检索和上下文示例优化单个LLM调用通常就足够了。
When and how to use frameworks
何时以及如何使用框架
There are many frameworks that make agentic systems easier to implement, including:
有很多框架使代理系统更容易实现,包括:
- LangGraph from LangChain;
- Amazon Bedrock’s AI Agent framework;
- Rivet, a drag and drop GUI LLM workflow builder; and
- Vellum, another GUI tool for building and testing complex workflows.
These frameworks make it easy to get started by simplifying standard low-level tasks like calling LLMs, defining and parsing tools, and chaining calls together. However, they often create extra layers of abstraction that can obscure the underlying prompts and responses, making them harder to debug. They can also make it tempting to add complexity when a simpler setup would suffice.
这些框架通过简化像调用LLMs、定义和解析工具以及链接调用等标准的底层任务,使入门变得容易。然而,它们常常会创建额外的抽象层,这可能会掩盖底层的提示和响应,使调试更加困难。它们也可能诱使开发者增加不必要的复杂性,即使简单的设置就足够了。
We suggest that developers start by using LLM APIs directly: many patterns can be implemented in a few lines of code. If you do use a framework, ensure you understand the underlying code. Incorrect assumptions about what’s under the hood are a common source of customer error.
我们建议开发者直接使用LLM API:很多模式只需几行代码即可实现。如果您确实使用了框架,请确保您理解底层代码。对底层代码的错误假设是客户错误的常见来源。
See our cookbook for some sample implementations. 请参阅我们的教程以获取一些示例实现。
Building blocks, workflows, and agents
构建块、工作流和代理
In this section, we’ll explore the common patterns for agentic systems we’ve seen in production. We’ll start with our foundational building block—the augmented LLM—and progressively increase complexity, from simple compositional workflows to autonomous agents.
在本节中,我们将探讨已在生产中看到的代理系统的常见模式。我们将从我们的基础构建块——增强的 LLM——开始,逐步增加复杂性,从简单的组合工作流到自主代理。
Building block: The augmented LLM
构建块:增强的 LLM
The basic building block of agentic systems is an LLM enhanced with augmentations such as retrieval, tools, and memory. Our current models can actively use these capabilities—generating their own search queries, selecting appropriate tools, and determining what information to retain.
代理系统的基本构建块是一个LLM,它通过检索、工具和记忆等增强功能得到强化。我们目前的模型可以主动使用这些功能——生成自己的搜索查询、选择合适的工具以及确定要保留的信息。
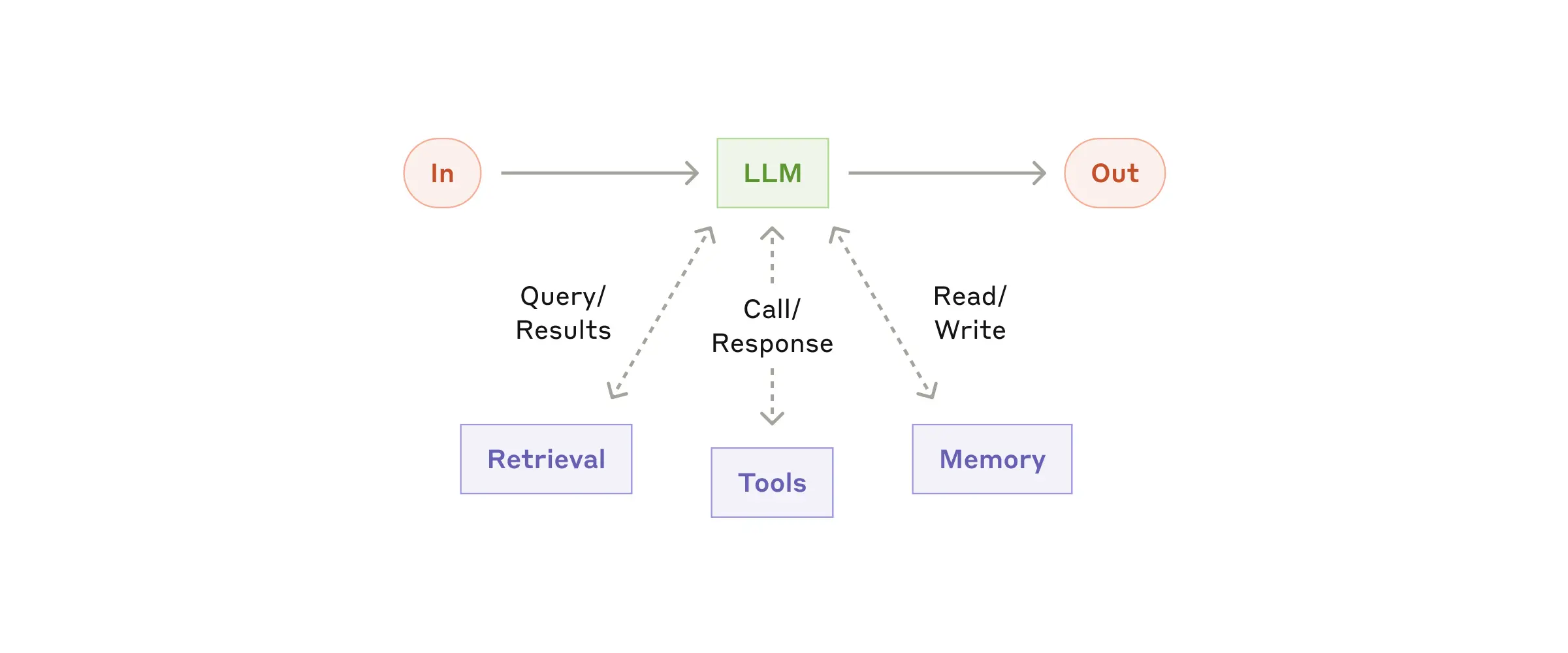 We recommend focusing on two key aspects of the implementation: tailoring these capabilities to your specific use case and ensuring they provide an easy, well-documented interface for your LLM. While there are many ways to implement these augmentations, one approach is through our recently released Model Context Protocol, which allows developers to integrate with a growing ecosystem of third-party tools with a simple client implementation.
We recommend focusing on two key aspects of the implementation: tailoring these capabilities to your specific use case and ensuring they provide an easy, well-documented interface for your LLM. While there are many ways to implement these augmentations, one approach is through our recently released Model Context Protocol, which allows developers to integrate with a growing ecosystem of third-party tools with a simple client implementation.
我们建议关注实施的两个关键方面:根据您的具体用例定制这些功能,并确保它们为您的LLM提供简单、文档完善的接口。虽然有很多方法可以实现这些增强,但一种方法是通过我们最近发布的模型上下文协议,该协议允许开发人员通过简单的客户端实现与不断增长的第三方工具生态系统集成。
For the remainder of this post, we’ll assume each LLM call has access to these augmented capabilities.
在本文的其余部分,我们将假设每个 LLM 调用都可以访问这些增强功能。
Workflow: Prompt chaining
工作流程:提示链
Prompt chaining decomposes a task into a sequence of steps, where each LLM call processes the output of the previous one. You can add programmatic checks (see “gate” in the diagram below) on any intermediate steps to ensure that the process is still on track.
提示链将一项任务分解成一系列步骤,其中每个 LLM 调用处理前一个步骤的输出。您可以在任何中间步骤添加程序化检查(请参见下图中的“gate”)以确保流程仍在正轨上。
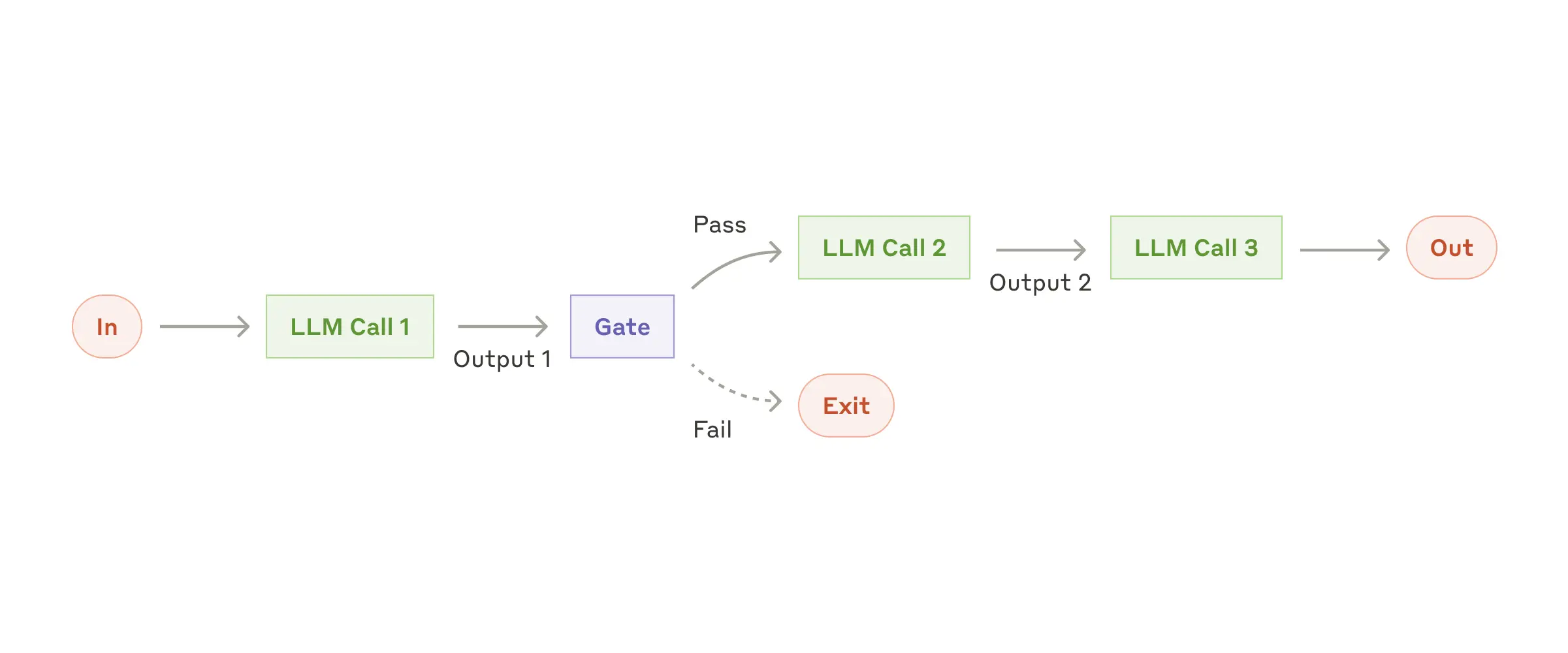
When to use this workflow: This workflow is ideal for situations where the task can be easily and cleanly decomposed into fixed subtasks. The main goal is to trade off latency for higher accuracy, by making each LLM call an easier task.
何时使用此工作流:此工作流适用于可以轻松、清晰地分解成固定子任务的情况。主要目标是通过使每次LLM调用成为更简单的任务,从而降低延迟并提高准确性。
Examples where prompt chaining is useful:
提示链有用的示例:
Generating Marketing copy, then translating it into a different language. 生成营销文案,然后将其翻译成不同的语言。
Writing an outline of a document, checking that the outline meets certain criteria, then writing the document based on the outline. 编写文档大纲,检查大纲是否符合特定标准,然后根据大纲编写文档。
Workflow: Routing
工作流程:路由
Routing classifies an input and directs it to a specialized followup task. This workflow allows for separation of concerns, and building more specialized prompts. Without this workflow, optimizing for one kind of input can hurt performance on other inputs.
路由将输入分类并将其定向到专门的后续任务。此工作流程允许分离关注点,并构建更专业的提示。如果没有此工作流程,针对一种输入进行优化可能会损害其他输入的性能。
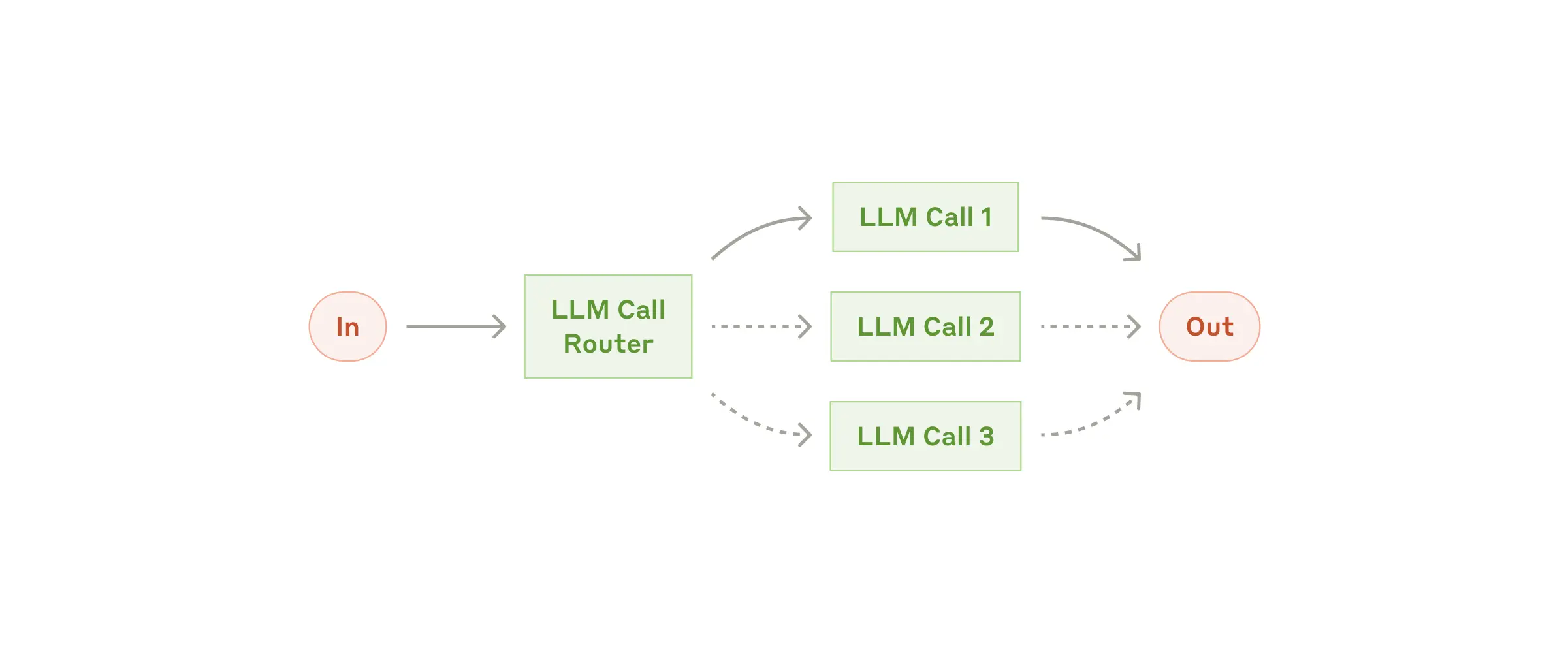 When to use this workflow: Routing works well for complex tasks where there are distinct categories that are better handled separately, and where classification can be handled accurately, either by an LLM or a more traditional classification model/algorithm.
When to use this workflow: Routing works well for complex tasks where there are distinct categories that are better handled separately, and where classification can be handled accurately, either by an LLM or a more traditional classification model/algorithm.
**何时使用此工作流程:**路由适用于存在不同类别的复杂任务,这些类别最好单独处理,并且可以通过 LLM 或更传统的分类模型/算法准确地进行分类。
Examples where routing is useful: 路由有用的示例:
- Directing different types of customer service queries (general questions, refund requests, technical support) into different downstream processes, prompts, and tools.
将不同类型的客户服务查询(一般问题、退款请求、技术支持)引导至不同的下游流程、提示和工具。
- Routing easy/common questions to smaller models like Claude 3.5 Haiku and hard/unusual questions to more capable models like Claude 3.5 Sonnet to optimize cost and speed.
将简单/常见问题路由到较小的模型,例如 Claude 3.5 Haiku,并将困难/不常见问题路由到功能更强大的模型,例如 Claude 3.5 Sonnet,以优化成本和速度。
Workflow: Parallelization
工作流程:并行化
LLMs can sometimes work simultaneously on a task and have their outputs aggregated programmatically. This workflow, parallelization, manifests in two key variations:
LLMs有时可以同时处理一项任务,并以编程方式聚合它们的输出。这种工作流程,即并行化,主要体现在两种变体中:
- Sectioning: Breaking a task into independent subtasks run in parallel.
分段:将任务分解成可并行运行的独立子任务。
- Voting: Running the same task multiple times to get diverse outputs.
投票:多次运行同一任务以获得不同的输出。
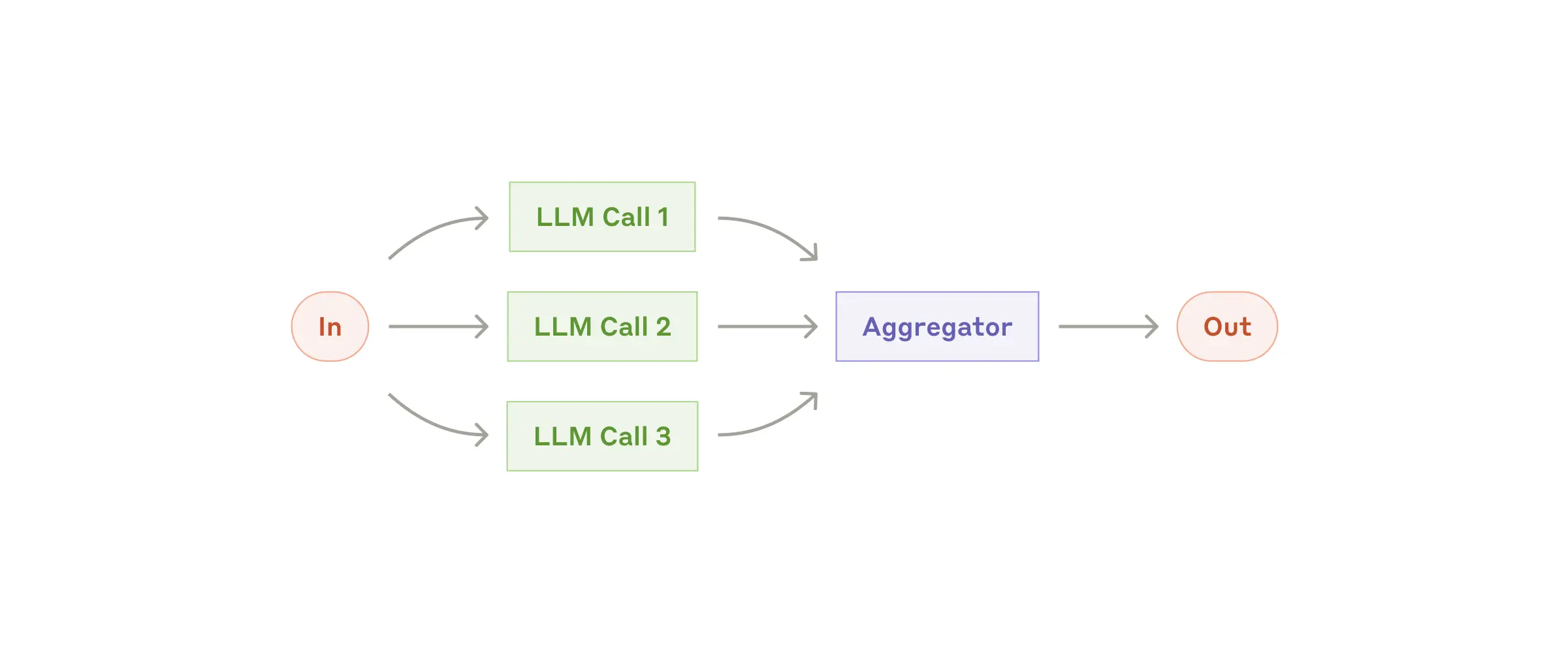 When to use this workflow: Parallelization is effective when the divided subtasks can be parallelized for speed, or when multiple perspectives or attempts are needed for higher confidence results. For complex tasks with multiple considerations, LLMs generally perform better when each consideration is handled by a separate LLM call, allowing focused attention on each specific aspect.
When to use this workflow: Parallelization is effective when the divided subtasks can be parallelized for speed, or when multiple perspectives or attempts are needed for higher confidence results. For complex tasks with multiple considerations, LLMs generally perform better when each consideration is handled by a separate LLM call, allowing focused attention on each specific aspect.
何时使用此工作流程:当划分后的子任务可以并行化以提高速度,或者需要多个视角或尝试以获得更高置信度的结果时,并行化是有效的。对于需要多方面考虑的复杂任务,LLMs通常在每个方面都由单独的LLM调用处理时表现更好,从而可以专注于每个特定方面。
Examples where parallelization is useful: 并行化有用的示例:
Sectioning: 分段:
- Implementing guardrails where one model instance processes user queries while another screens them for inappropriate content or requests. This tends to perform better than having the same LLM call handle both guardrails and the core response.
实现防护机制,其中一个模型实例处理用户查询,而另一个模型实例筛选不适当的内容或请求。这种方法的性能往往优于由同一个LLM调用同时处理防护机制和核心响应。
- Automating evals for evaluating LLM performance, where each LLM call evaluates a different aspect of the model’s performance on a given prompt.
自动评估LLM的性能,其中每次LLM调用都会评估模型在给定提示下不同方面的性能。
Voting: 投票:
- Reviewing a piece of code for vulnerabilities, where several different prompts review and flag the code if they find a problem.
审查一段代码是否存在漏洞,其中几个不同的提示会审查代码,并在发现问题时标记。
- Evaluating whether a given piece of content is inappropriate, with multiple prompts evaluating different aspects or requiring different vote thresholds to balance false positives and negatives.
评估一段给定内容是否不恰当,使用多个提示评估不同方面或要求不同的投票阈值以平衡误报和漏报。
Workflow: Orchestrator-workers
工作流:协调器-工作器
In the orchestrator-workers workflow, a central LLM dynamically breaks down tasks, delegates them to worker LLMs, and synthesizes their results.
在协调器-工作器工作流程中,中央LLM动态地分解任务,将它们委派给工作器LLMs,并综合它们的结果。
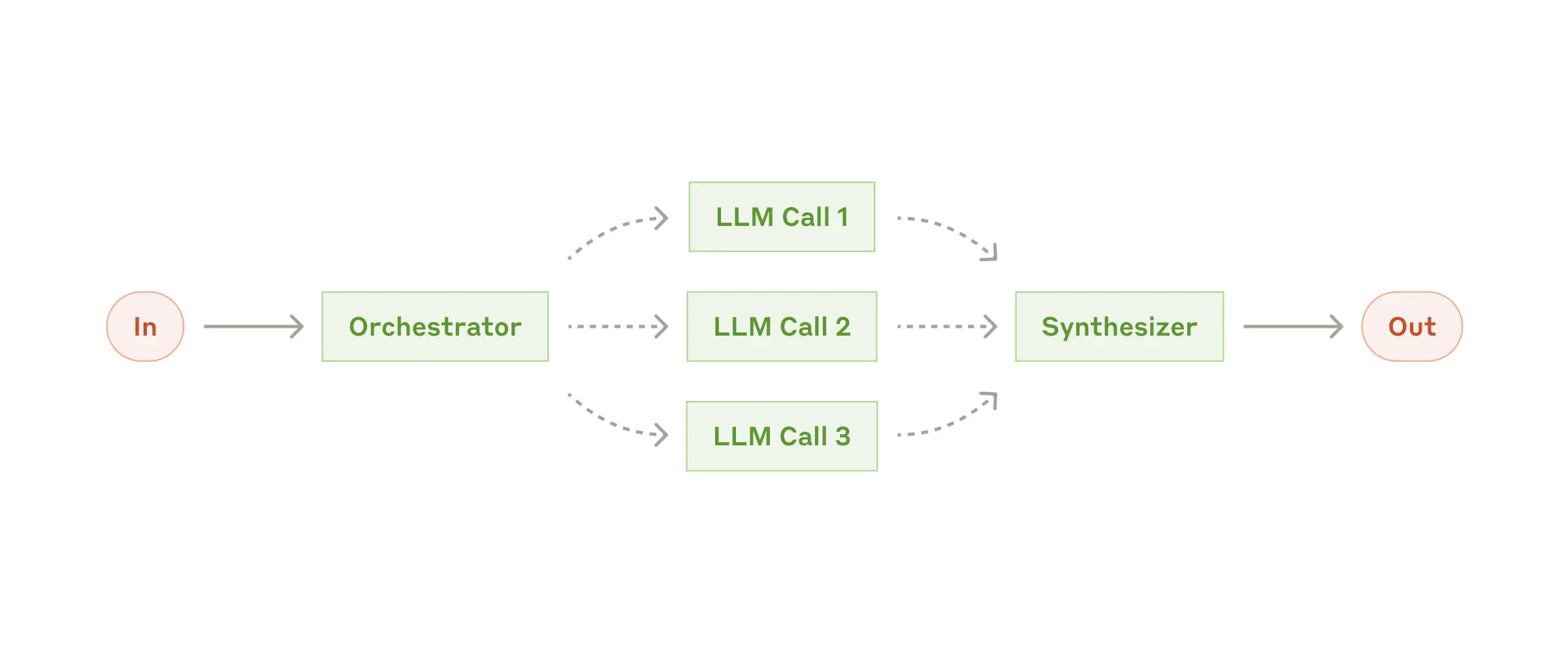 When to use this workflow: This workflow is well-suited for complex tasks where you can’t predict the subtasks needed (in coding, for example, the number of files that need to be changed and the nature of the change in each file likely depend on the task). Whereas it’s topographically similar, the key difference from parallelization is its flexibility—subtasks aren’t pre-defined, but determined by the orchestrator based on the specific input.
When to use this workflow: This workflow is well-suited for complex tasks where you can’t predict the subtasks needed (in coding, for example, the number of files that need to be changed and the nature of the change in each file likely depend on the task). Whereas it’s topographically similar, the key difference from parallelization is its flexibility—subtasks aren’t pre-defined, but determined by the orchestrator based on the specific input.
**何时使用此工作流:**此工作流非常适用于无法预测所需子任务的复杂任务(例如,在编码中,需要更改的文件数量以及每个文件中更改的性质可能取决于任务)。虽然它在拓扑上相似,但与并行化的关键区别在于它的灵活性——子任务不是预先定义的,而是由协调器根据特定输入确定的。
Example where orchestrator-workers is useful: 协调器-工作器机制有用的示例:
- Coding products that make complex changes to multiple files each time.
对多个文件进行复杂更改的编码产品。
- Search tasks that involve gathering and analyzing information from multiple sources for possible relevant information.
搜索需要从多个来源收集和分析信息的任务,以查找可能的相关信息。
Workflow: Evaluator-optimizer
工作流程:评估器-优化器
In the evaluator-optimizer workflow, one LLM call generates a response while another provides evaluation and feedback in a loop.
在评估器-优化器工作流程中,一次LLM调用生成一个响应,而另一个则在循环中提供评估和反馈。
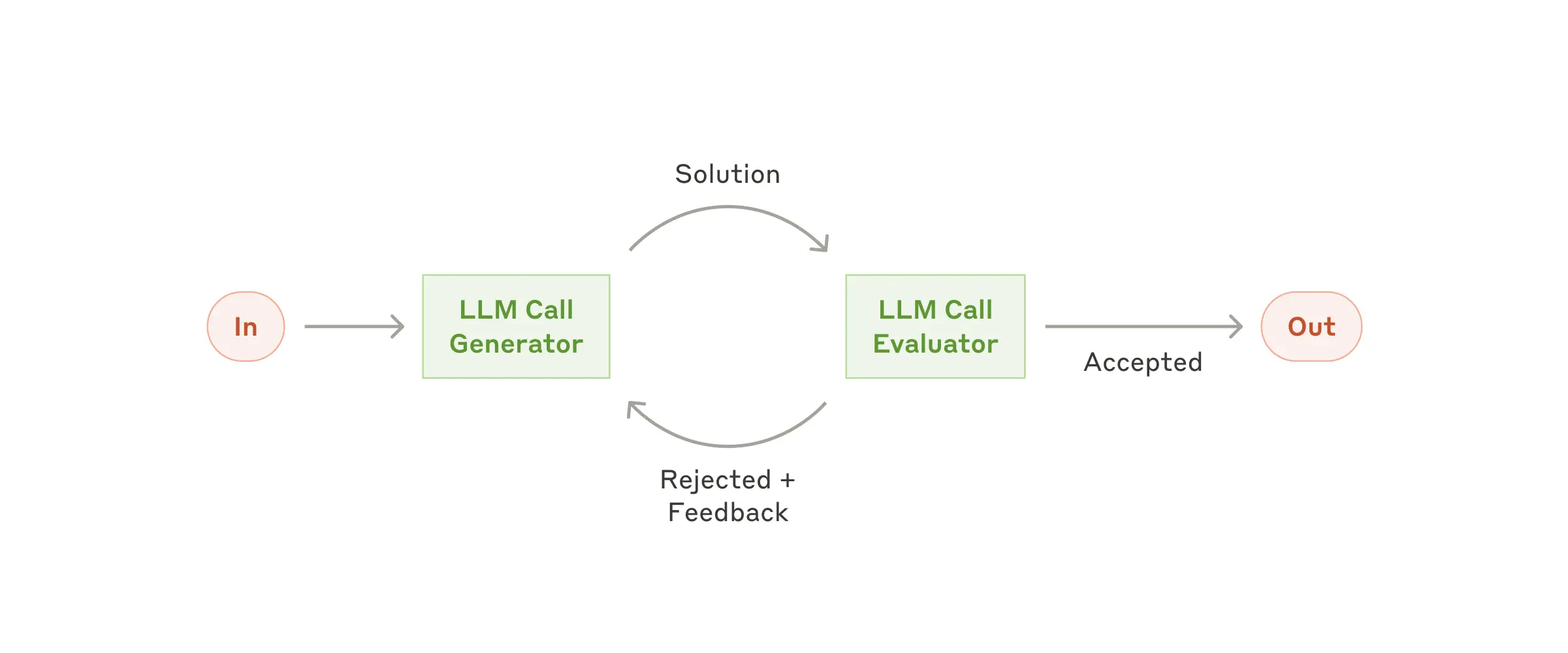
When to use this workflow: This workflow is particularly effective when we have clear evaluation criteria, and when iterative refinement provides measurable value. The two signs of good fit are, first, that LLM responses can be demonstrably improved when a human articulates their feedback; and second, that the LLM can provide such feedback. This is analogous to the iterative writing process a human writer might go through when producing a polished document. ***何时使用此工作流程:***当我们有明确的评估标准,并且迭代改进可以提供可衡量的价值时,此工作流程特别有效。 两个良好匹配的标志是,首先,当人工表达他们的反馈时,LLM响应可以得到明显的改进;其次,LLM可以提供此类反馈。这类似于人类作家在撰写精美文档时可能经历的迭代写作过程。
Examples where evaluator-optimizer is useful: 评估器-优化器有用的例子:
- Literary translation where there are nuances that the translator LLM might not capture initially, but where an evaluator LLM can provide useful critiques.
文学翻译中存在译者LLM最初可能无法捕捉到的细微之处,但评估者LLM可以提供有用的评论。
- Complex search tasks that require multiple rounds of searching and analysis to gather comprehensive information, where the evaluator decides whether further searches are warranted.
需要多轮搜索和分析才能收集全面信息的复杂搜索任务,由评估人员决定是否需要进一步搜索。
Agents 代理人
Agents are emerging in production as LLMs mature in key capabilities—understanding complex inputs, engaging in reasoning and planning, using tools reliably, and recovering from errors. Agents begin their work with either a command from, or interactive discussion with, the human user. Once the task is clear, agents plan and operate independently, potentially returning to the human for further information or judgement. During execution, it’s crucial for the agents to gain “ground truth” from the environment at each step (such as tool call results or code execution) to assess its progress. Agents can then pause for human feedback at checkpoints or when encountering blockers. The task often terminates upon completion, but it’s also common to include stopping conditions (such as a maximum number of iterations) to maintain control.
代理正在生产环境中涌现,因为LLMs在关键能力方面已经成熟——理解复杂输入、进行推理和规划、可靠地使用工具以及从错误中恢复。代理通过来自人类用户的命令或与人类用户的交互式讨论开始他们的工作。一旦任务明确,代理就会独立计划和操作,可能会返回给人类以获取更多信息或判断。在执行过程中,代理在每个步骤(例如工具调用结果或代码执行)中从环境中获取“基本事实”以评估其进度至关重要。代理可以在检查点或遇到障碍时暂停以获得人工反馈。任务通常在完成后终止,但也通常包含停止条件(例如最大迭代次数)以保持控制。
Agents can handle sophisticated tasks, but their implementation is often straightforward. They are typically just LLMs using tools based on environmental feedback in a loop. It is therefore crucial to design toolsets and their documentation clearly and thoughtfully. We expand on best practices for tool development in Appendix 2 (“Prompt Engineering your Tools”).
代理可以处理复杂的任务,但它们的实现通常很简单。它们通常只是LLMs在一个循环中使用基于环境反馈的工具。因此,清晰且周到地设计工具集及其文档至关重要。我们会在附录 2(“提示工程你的工具”)中详细阐述工具开发的最佳实践。
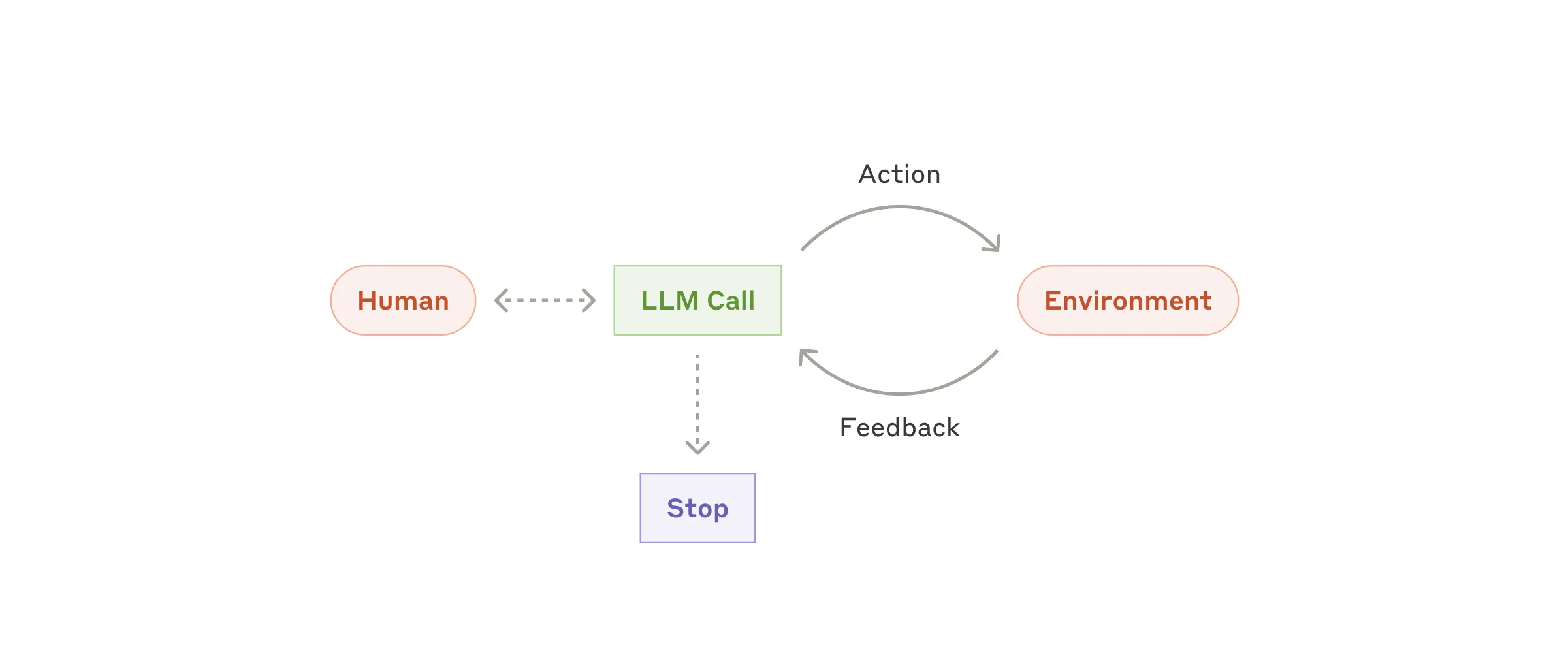
When to use agents: Agents can be used for open-ended problems where it’s difficult or impossible to predict the required number of steps, and where you can’t hardcode a fixed path. The LLM will potentially operate for many turns, and you must have some level of trust in its decision-making. Agents’ autonomy makes them ideal for scaling tasks in trusted environments.
**何时使用代理:**代理可用于难以或不可能预测所需步骤数的开放式问题,以及无法硬编码固定路径的情况。LLM可能会运行多个回合,您必须对其决策有一定程度的信任。代理的自主性使其非常适合在受信任的环境中扩展任务。
The autonomous nature of agents means higher costs, and the potential for compounding errors. We recommend extensive testing in sandboxed environments, along with the appropriate guardrails.
代理的自主性意味着更高的成本,以及潜在的复合错误。我们建议在沙盒环境中进行广泛的测试,并设置适当的防护措施。
The following examples are from our own implementations: 以下示例来自我们自己的实现:
- A coding Agent to resolve SWE-bench tasks, which involve edits to many files based on a task description;
一个负责解决 SWE-bench 任务的编码代理,这些任务涉及根据任务描述对许多文件进行编辑;
- Our “computer use” reference implementation, where Claude uses a computer to accomplish tasks.
我们的“计算机使用”参考实现,其中 Claude 使用计算机来完成任务。
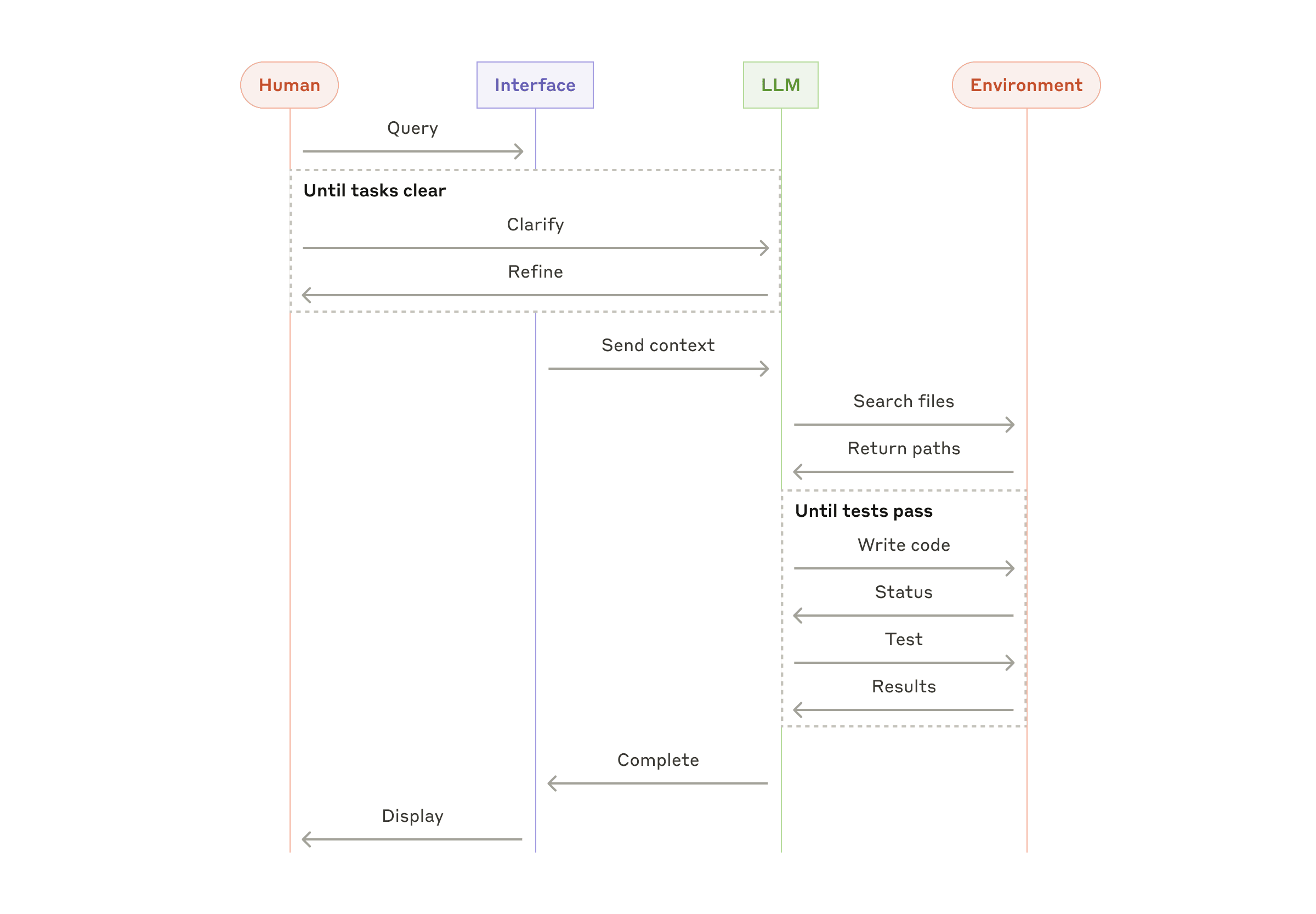
Combining and customizing these patterns
组合和自定义这些模式
These building blocks aren’t prescriptive. They’re common patterns that developers can shape and combine to fit different use cases. The key to success, as with any LLM features, is measuring performance and iterating on implementations. To repeat: you should consider adding complexity only when it demonstrably improves outcomes.
这些构建块并非规范性的。它们是开发者可以调整和组合以适应不同用例的常见模式。与任何LLM功能一样,成功的关键在于衡量性能并迭代实现。再次强调:只有当复杂性能够显著改善结果时,才应该考虑添加。
Summary
总结
Success in the LLM space isn’t about building the most sophisticated system. It’s about building the right system for your needs. Start with simple prompts, optimize them with comprehensive evaluation, and add multi-step agentic systems only when simpler solutions fall short.
在LLM领域取得成功并非在于构建最复杂的系统,而在于构建适合您需求的系统。从简单的提示词入手,通过全面的评估来优化它们,并且仅当简单的解决方案不足时才添加多步骤代理系统。
When implementing agents, we try to follow three core principles:
在实现代理时,我们尝试遵循三个核心原则:
Maintain simplicity in your agent’s design. 保持代理设计的简洁性。
Prioritize transparency by explicitly showing the agent’s planning steps. 优先考虑透明度,明确显示代理的计划步骤。
Carefully craft your agent-computer interface (ACI) through thorough tool documentation and testing. 仔细设计您的代理-计算机界面 (ACI),并进行全面的工具记录和测试。
Frameworks can help you get started quickly, but don’t hesitate to reduce abstraction layers and build with basic components as you move to production. By following these principles, you can create agents that are not only powerful but also reliable, maintainable, and trusted by their users.
框架可以帮助你快速入门,但当你转向生产环境时,不要犹豫降低抽象层级,使用基本组件进行构建。遵循这些原则,你就可以创建出功能强大、可靠、易于维护并且值得用户信赖的代理。